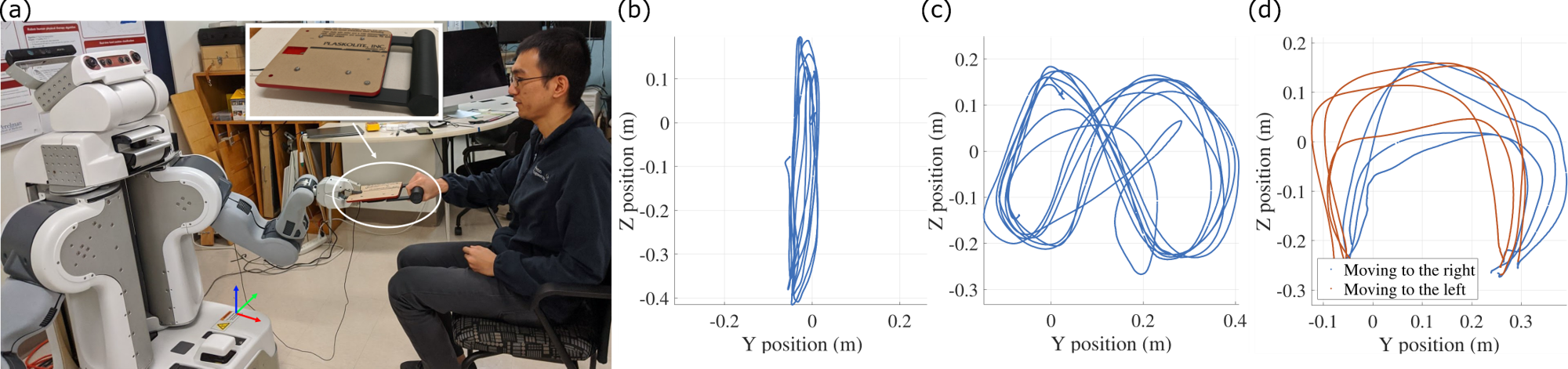
(a) A user sitting in front of the PR2 robot. They each use one hand to hold an object that was specifically designed for upper-limb exercises for patients with stroke. Example trajectories from the (b) 1D, (c) 2D, and (d) pick-and-place exercises tested in the study.
Compared to conventional upper-limb therapies, robotic devices can offer multiple advantages in physical training and rehabilitation. Automation can reduce the workload of rehabilitation professionals and augment their ability to provide care to patients by facilitating intensive and repeatable exercise. Additionally, robots can provide objective assessments of a patient’s progress using onboard sensors.
In the scope of this research, we developed a learning-from-demonstration (LfD) technique that enables a general-purpose humanoid robot to lead a user through object-mediated upper-limb exercises [ ]. Built upon our prior research [ ], our approach requires only tens of seconds of training data from a therapist teleoperating the robot to do the task with the user.
We model the robot behavior as a regression problem: during training, the joint distribution of robot position, velocity, and effort (force output at the end-effector) are modeled by a Gaussian mixture model (GMM), and during testing, desired robot effort is regressed from the current state (position and velocity) from the GMM. Compared to the conventional approach of learning time-based trajectories, our state-based strategy produces customized robot behavior and eliminates the need to tune gains to adapt to the user’s motor ability.
This approach was evaluated through a user study involving one occupational therapist and six people with stroke [ ]. The therapist trained a Willow Garage PR2 on three example tasks for each client: i) periodic 1D motions, ii) periodic 2D motions, and iii) episodic pick and place operations. Both the person with stroke and the therapist then repeatedly performed the tasks alone with the robot and blindly compared the state- and time-based controllers learned from the training data.
Our results show that working models were reliably learned to enable the robot to do the exercise with the user. Furthermore, our state-based approach enabled users to be more actively involved, allowed larger excursion, and generated power outputs more similar to the therapist demonstrations. Finally, the therapist found our strategy more agreeable than the traditional time-based approach. More detailed descriptions of this project’s algorithms and results can be found in the Ph.D. thesis of Siyao Hu [ ].